Discover the Future of Natural Language Queries with Table-Augmented Generation (TAG)
Picture yourself as a business analyst trying to decipher why your company’s sales plummeted last quarter. You type a straightforward question into your database: “Why did sales drop last quarter?” Ideally, an AI system would instantly deliver a meaningful, well-rounded answer — pulling together all relevant data points, trends, and market insights. Unfortunately, the current reality doesn’t quite match up to this ideal.
Today’s AI methods for querying databases, like Text2SQL and Retrieval-Augmented Generation (RAG), have significant limitations. Text2SQL translates natural language into SQL queries, while RAG relies on simple data lookups, neither of which can handle the complexity or depth needed for real-world inquiries.
Why is this important? With the rise of Large Language Models (LLMs), using natural language to query SQL databases has become increasingly popular. Despite being inundated with data, businesses are struggling to extract actionable insights. This failure to effectively combine AI’s semantic reasoning with databases’ computational power is a key barrier to making data useful. We need an innovative solution that comprehends and answers diverse user questions more effectively.
However, using natural language in this way presents its own set of challenges:
- Text2SQL: Converts natural language queries into SQL. This works for simple questions like “What were the total sales last quarter?” but struggles with complex reasoning or questions that require knowledge not explicitly recorded in the database, such as “Which customer reviews of product X are positive?”
- Retrieval-Augmented Generation (RAG): Uses AI to find relevant data records but is confined to basic lookups and can’t handle complex computations. When faced with high data volumes or multi-faceted questions, RAG often misses the mark.
Imagine needing to analyze customer reviews, sales data, and market sentiment simultaneously. Text2SQL cannot process free-text data, and RAG is inefficient with large datasets, often producing inaccurate or incomplete answers when it doesn’t fully understand the user’s query intent or the target database.
These limitations mean that many user queries remain unanswered, creating a substantial gap in real-world applicability.
Introducing Table-Augmented Generation (TAG)
TAG is a revolutionary approach developed by researchers from Stanford and Berkeley, aimed at overcoming the shortcomings of the Text2SQL method. Check out their research paper here: https://arxiv.org/abs/2408.14717
Here’s how TAG works:
- Query Synthesis: Converts the user’s natural language request into an executable database query. Unlike Text2SQL, TAG can generate complex queries that blend multiple data sources and types.
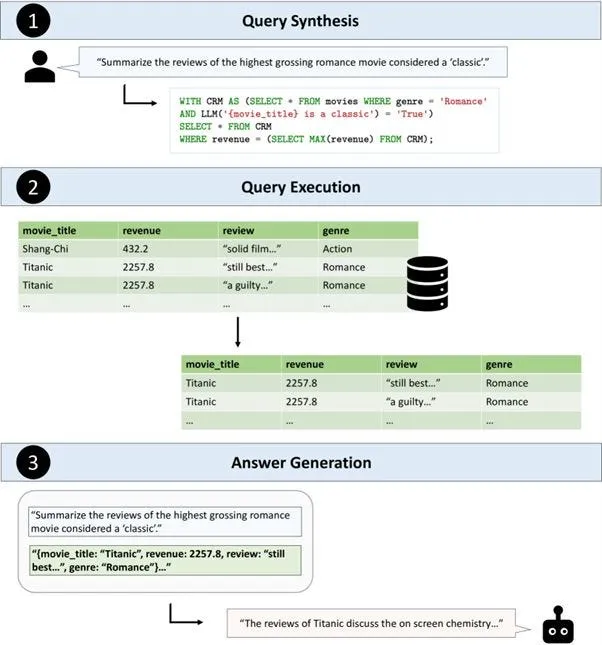
Observe how the query “Summarize the reviews of the highest-grossing romance movie considered a ‘classic’” is translated into:
WITH CRM AS (SELECT * FROM movies WHERE genre = 'Romance'
AND LLM('{movie_title} is a classic') = 'True')
SELECT * FROM CRM
WHERE revenue = (SELECT MAX(revenue) FROM CRM);
TAG introduces the line LLM(‘{movie_title} is a classic’) = ‘True’ in the query, representing the “Augmentation” step since the database does not natively provide the necessary context.
- Query Execution: Executes the synthesized query against the database, leveraging its computational power for efficient large-scale data retrieval and exact computations.
- Answer Generation: Utilizes the retrieved data to generate a contextually rich answer, combining semantic reasoning, world knowledge, and domain-specific insights acquired during the augmentation step.
An essential component behind TAG’s effectiveness is the LOTUS framework.
LOTUS: The Powerhouse Behind TAG
To make TAG successful, a robust framework is necessary — one that seamlessly integrates AI with traditional database systems. This is where LOTUS (Leveraging Optimization Techniques for Unifying Semantic Queries) comes in. LOTUS bridges the gap between the reasoning capabilities of large language models (LLMs) and the computational prowess of databases, enabling complex and meaningful data queries.
Understanding LOTUS
LOTUS is a pioneering framework that enables Table-Augmented Generation by allowing semantic queries over datasets containing both structured and unstructured data. It directly integrates LLMs into the database query pipeline, combining the strengths of advanced AI with high-performance data management.
Key Features of LOTUS
- Semantic Operators for Enhanced Queries: Introduces AI-based functions for tasks like filtering, ranking, and aggregation using natural language processing. For example, LOTUS can use a language model to filter rows based on positive sentiment, going beyond traditional SQL capabilities.
- Optimized Query Execution: Features an optimized semantic query execution engine, reducing latency and boosting performance by efficiently executing complex queries that involve both traditional SQL and LLM operations.
- Flexibility and Customization: Allows developers to create custom query pipelines that integrate SQL operations with AI capabilities. For instance, a financial query could retrieve historical stock data and analyze recent news sentiment simultaneously.
- Supporting the TAG Framework: Acts as the backbone for the TAG model, managing complex multi-step queries that require both database computations and LLM reasoning, thus providing comprehensive and well-grounded answers.
More about LOTUS can be explored here: https://github.com/TAG-Research/lotus
The GitHub link offers excellent examples of using LOTUS for semantic joins. I’m planning to dive into it soon — stay tuned for more in an upcoming post!
Thanks for reading!