DeepAI’s Big Data Pipeline: Understanding, Designing, and Building Efficient Data Flows
Even before launching our startup DeepAI back in 2020, we encountered significant challenges in managing and storing large datasets. To address these, we began experimenting with various approaches and services to find the most effective solutions.
Today, to meet the specific needs of our projects and clients, we have developed a specialized pipeline tailored to handle vast data schemas. Whether creating large datasets for training new LLM models or fine-tuning existing ones, building an efficient big data pipeline not only simplifies and scales workflows but also significantly reduces service and infrastructure costs.
I’m excited to share with you a set of ready-to-deploy big data pipeline templates that we use at DeepAI across multiple projects. For simplicity, this post will focus on Amazon AWS and Google Cloud, our team’s most frequently used platforms.
Happy building!
What is a Data Pipeline?
A data pipeline is a sophisticated system designed to automate the movement, transformation, and management of data. It encompasses various technologies that help verify, summarize, and identify patterns within the data, ultimately informing crucial business decisions. Well-crafted data pipelines enable organizations to support a wide range of big data initiatives, including data visualizations, exploratory data analysis, and advanced machine learning tasks.
By effectively managing data flow from one point to another, data pipelines ensure that relevant insights can be extracted efficiently.
AWS Big Data pipeline
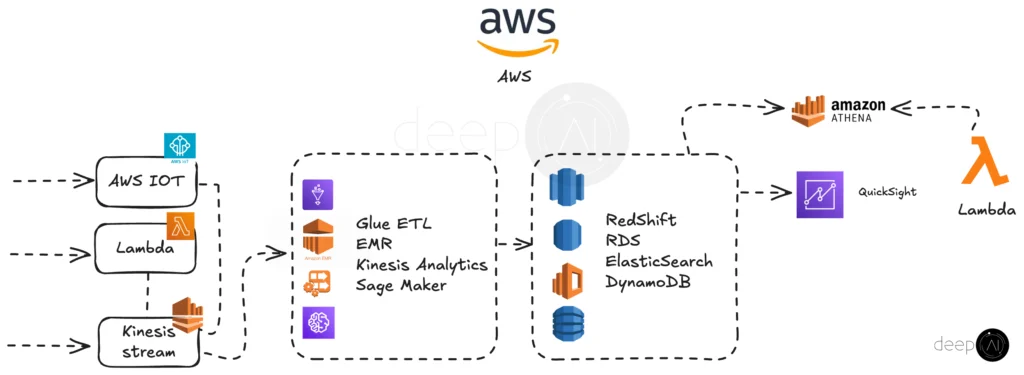
Our AWS-based big data pipeline processes and analyzes streaming data in real-time. The data flows through three main entry points: AWS IoT, Lambda, and Kinesis Stream. These feed into processing services like Glue ETL, EMR, Kinesis Analytics, and SageMaker for data transformation, analytics, and machine learning.
Processed data is stored in databases such as Redshift, RDS, Elasticsearch, and DynamoDB, depending on the specific use case. For querying, Amazon Athena provides interactive analysis, while QuickSight enables data visualization and insights.
Additional Lambda functions support automation and integration across the pipeline, ensuring seamless data flow and scalable processing capabilities.
Google Cloud Big Data pipeline
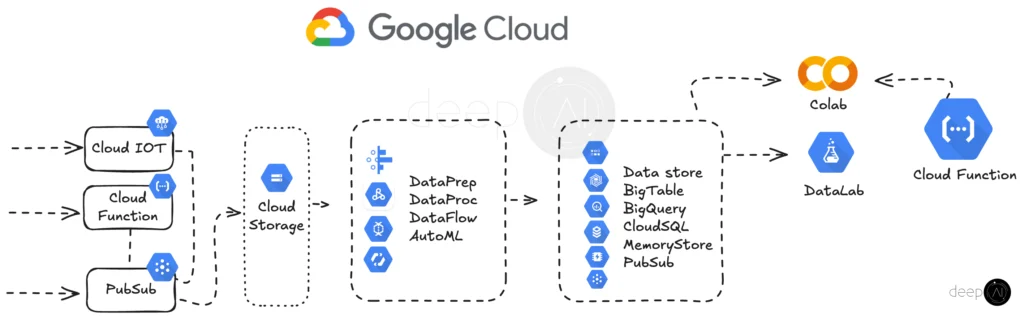
Our Google Cloud big data pipeline is designed to handle real-time data ingestion and processing. Data enters through Cloud IoT, Cloud Function, or Pub/Sub, which feed into Cloud Storage for centralized data management. Data processing and transformation are handled by DataPrep, DataProc, DataFlow, and AutoML to prepare the data for further analysis.
Processed data is stored across various Google Cloud databases, such as BigTable, BigQuery, Cloud SQL, MemoryStore, and Pub/Sub, depending on the data requirements. For analysis and machine learning, Colab and DataLab provide platforms for experimentation and model building.
Additional Cloud Functions support automated processes and seamless integration across the pipeline.
Stages in a Data Pipeline
The architecture of a data pipeline typically consists of three main stages: Source, Processing, and Destination. Understanding these stages is critical to harnessing the full potential of data pipelines. The phases involved in a big data analysis pipeline are:
- Data Ingestion: This initial stage involves collecting data from various sources, which may include databases, applications, sensors, or log files. The diversity of these sources contributes to the richness of the data.
- Data Transformation: After ingestion, the raw data undergoes cleaning, structuring, and enrichment. This ensures that the data is accurate, consistent, and ready for further analysis.
- Data Loading: Finally, the processed data is delivered to its intended destination, such as a data warehouse or data lake, where it can be accessed for analysis and reporting.
Data Pipeline vs ETL Pipeline
While data pipelines and ETL (Extract, Transform, Load) pipelines share similarities, they serve different purposes. The primary distinction lies in how ETL pipelines manage data transformation and transfer. ETL pipelines focus on transforming data into a more analyzable format and typically transfer it to another destination at scheduled intervals. This structured approach to data movement impacts how businesses design their data management strategies and can influence overall efficiency in operations.
Components of a Big Data Pipeline
A robust big data pipeline efficiently manages high volumes of data moving at speed while handling data from multiple sources. A well-thought-out data pipeline consists of several key components, including:
- Storage: This refers to the infrastructure where data is stored, including data lakes, data warehouses, or cloud storage solutions.
- Preprocessing: At this stage, initial data cleaning and validation occur to ensure data quality before further processing.
- Analysis: In this phase, insights are extracted from the processed data, often employing statistical analysis, machine learning, or data visualization techniques.
- Applications: This encompasses the various use cases of the processed data, such as dashboards, reports, or predictive analytics.
- Delivery: The final step involves sending the data to its intended destination, ensuring that stakeholders have timely access to relevant information.
Designing Data Pipeline Architecture
Designing a data pipeline architecture involves a systematic approach to creating and managing the flow of data from diverse sources to distinct destinations. This architecture is developed through both logical and platform-level designs, specifying processing and transformation methodologies alongside their technical frameworks. The key characteristics of an effective data pipeline architecture include:
- Access: Ensuring that users have the ability to access their data as needed.
- Elasticity: The architecture should adjust to varying workloads and demands efficiently.
- Continuous Processing: A well-designed pipeline should facilitate real-time data processing, enabling businesses to act on insights swiftly.
- Data Source Flexibility: The ability to integrate and connect to multiple data sources seamlessly enhances the pipeline’s effectiveness.
Types and Use Cases of Data Pipelines
Data pipelines serve various purposes, with their primary function being data integration—bringing together data from multiple sources for meaningful analysis. Depending on their overall structure, there are two primary types of data pipelines:
- Batch Processing Pipelines: These pipelines handle historical data by collecting it into batches and processing it at scheduled intervals or on-demand.
- Streaming Pipelines: Designed for real-time data ingestion and processing, streaming pipelines maintain low latency to support immediate analytics—essential for applications such as fraud detection or real-time monitoring systems.
Technologies for Building Data Pipelines
Several essential technologies play a role in the construction of data pipelines, enabling automation and efficient management of data processing workloads. Notable technologies include:
- Free and Open-Source Software (FOSS): Many organizations utilize FOSS to streamline their data pipeline processes without incurring licensing costs.
- MapReduce: Often employed for processing large datasets across clusters of computers, MapReduce facilitates distributed computing seamlessly.
- Apache Hadoop: A popular framework that enables distributed storage and processing of large datasets.
- Apache Pig: A platform for analyzing large data sets that streamlines tasks that involve complex data transformations.
- Apache Hive: A data warehouse software that enables querying and managing large datasets residing in distributed storage using a SQL-like interface.
Batch Processing vs. Streaming Data Pipelines
When it comes to data processing, understanding the difference between batch processing and streaming data pipelines can inform the design of an effective data pipeline:
- Batch Processing: Suited for scenarios where large volumes of historical data can be processed at consistent intervals, batch pipelines enable organizations to leverage non-time-sensitive tasks efficiently.
- Streaming Pipelines: These pipelines are critical when real-time data ingestion and processing are necessary. They ensure rapid analytics and facilitate immediate action, making them ideal for applications requiring low latency.
Building a Robust Data Pipeline
To develop an effective data pipeline, a methodical process should be followed:
- Define Your Goals: Clearly outline the purpose of the pipeline to ensure alignment with business needs.
- Identify Data Sources: Determine the origins of your data, factoring in both internal and external sources.
- Determine the Data Ingestion Strategy: Choose suitable methods for collecting and processing data based on its volume, variety, and velocity.
Additionally, emphasizing reproducibility guarantees that the data pipeline can meet varying business needs effectively while adapting to changes in data requirements.