DeepSeek R1 Architecture and Training Workflow from Scratch
If you’ve been keeping up with artificial intelligence, you might have heard about DeepSeek R1. It’s one of the newest players in the large language model (LLM) game and is really making a name for itself by outshining both open-source and proprietary models.
To make things easier to understand, we’ll break everything down with hand-drawn flowcharts and simple calculations. This way, every concept will be clear from the start. We’ll use the example “What is 2 + 3 * 4?” to help explain the key points in the DeepSeek R1 technical report.
A Quick Overview — How DeepSeek R1 Came to Life
Before we dive into the details, let’s talk about how DeepSeek R1 was created. Unlike some models that start from scratch, this one built on an existing model called DeepSeek V3. The researchers improved its reasoning abilities instead of starting from zero.
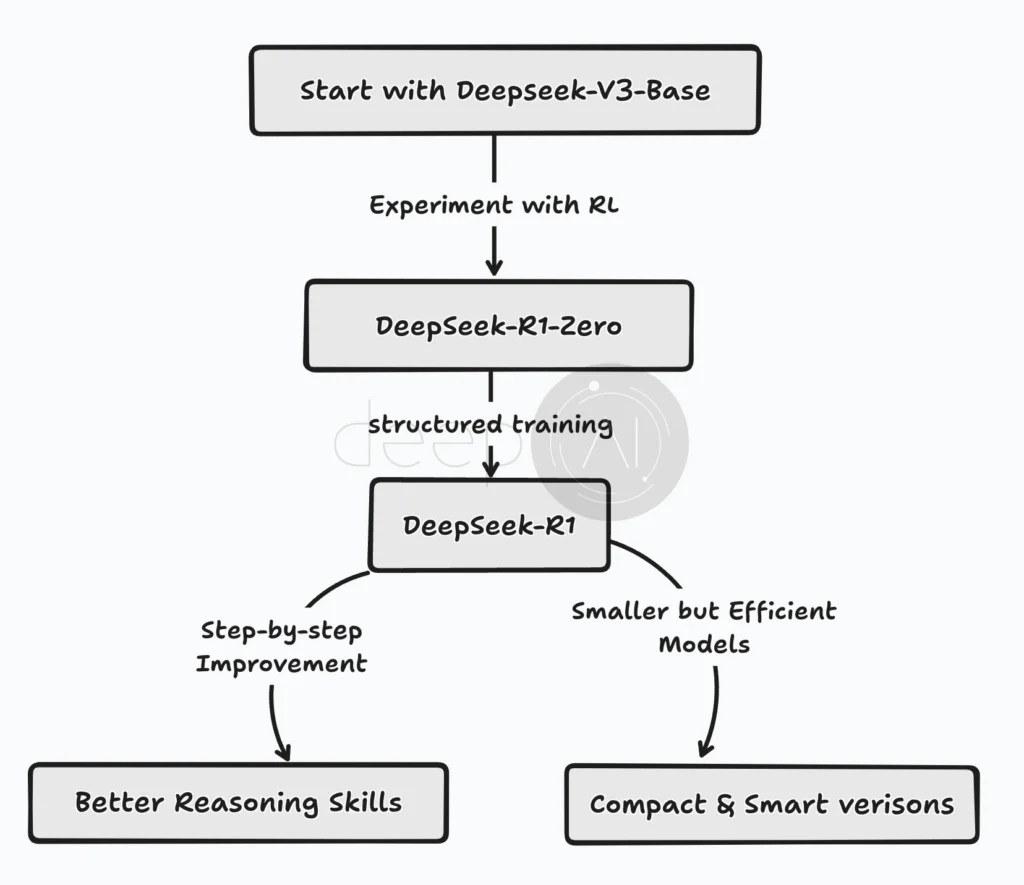
They used a method called Reinforcement Learning (RL), where the model gets rewards for showing good reasoning skills and penalties for not doing well. But it wasn’t just a simple training session. They followed a structured, multi-stage approach. The first experiment, called DeepSeek R1 Zero, relied solely on RL to see if the model could learn reasoning on its own.
Later, for the full DeepSeek R1, they set up a more organized training process. This involved giving the model initial data, applying RL, adding more data, refining it with additional RL cycles, and repeating the process—kind of like leveling up in a game.
The main goal? To help LLMs think critically and come up with smart responses, rather than just repeating words. That’s the big picture before we get into the finer details of each step.
How DeepSeek V3 (MOE) Thinks?
Since DeepSeek R1 is built on DeepSeek V3, it’s important to understand how V3 works. But why is it called an MOE (Mixture of Experts) model?
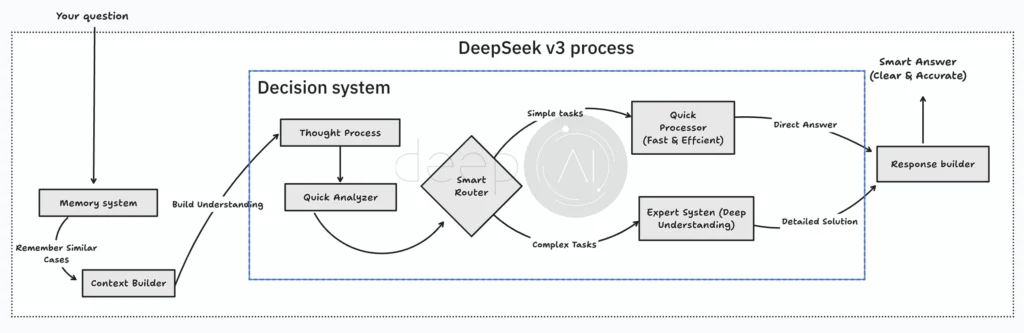
Well, DeepSeek V3 uses a dual-path approach when it processes input. When it gets a question, it first uses a memory system to pull up relevant context—kind of like how we remember related experiences when faced with a new problem.
Its real strength is in decision-making. After processing the input, it uses a smart routing system to find the best way to handle it:
- A fast pathway for simple, common questions.
- An expert pathway for complex problems that need deeper reasoning.
This Mixture of Experts approach lets DeepSeek V3 allocate resources dynamically, ensuring the right expert tackles each request. Basic questions get quick answers, while tougher ones are handled by specialized networks, leading to detailed and well-thought-out responses.
Finally, the system combines results from both pathways to give a complete and accurate answer.
DeepSeek V3 as the RL Agent (Actor) in DeepSeek R1
Now that we know about DeepSeek V3, let’s see how it supports DeepSeek R1’s training. The researchers started with DeepSeek R1 Zero, an initial version trained using Reinforcement Learning, before refining it into the final model.
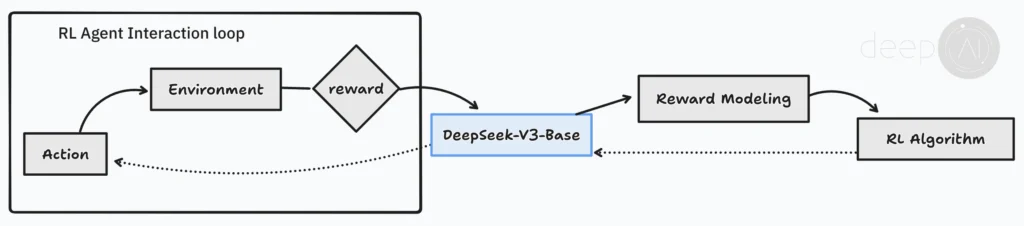
Here’s how the RL setup works:
- DeepSeek V3 acts as the “Agent” (or Actor). It generates answers and reasoning for a given problem.
- The “Environment” gives feedback, which in this case is the reasoning task itself.
- A Reward system evaluates the responses. If the model gives a good answer with solid reasoning, it gets a positive reward. If not, it gets a negative one.
This feedback helps improve future responses. The rewards guide the model’s learning, allowing it to refine its approach and produce smarter, more logical answers over time. In the next sections, we’ll look at how this reward-based training system works, along with the specific RL algorithms used.
How GRPO Optimizes Reinforcement Learning for LLMs
Training large language models is already a heavy task, and adding Reinforcement Learning makes it even more complex. Traditional RL methods use a Critic model to evaluate the main decision-making system (the Actor, which is DeepSeek V3), but this doubles the computational load.
This is where GRPO (Generalized Reward Policy Optimization) comes in. It takes a more efficient approach by getting rid of the need for a separate Critic model.
How GRPO Works
- The model (Old Policy) gets an input prompt.
- Instead of giving just one answer, it generates several possible responses.
- Each answer is evaluated and given a reward score based on its quality.
- GRPO calculates an “Advantage Score” for each response by comparing it to the average quality of the group.
- If a response is better than average, it gets a positive advantage; if it’s worse, it gets a negative one.
The model is updated based on this, favoring high-quality answers. This refined model then becomes the new “Old Policy,” and the process repeats, continuously improving performance.
Eliminating the need for a separate Critic model, GRPO significantly cuts down on computational costs while still enhancing reasoning and decision-making skills.
Objective Function of GRPO
Let’s talk about the objective function of GRPO. It sounds complicated, but we can break it down into simpler terms without losing its meaning.
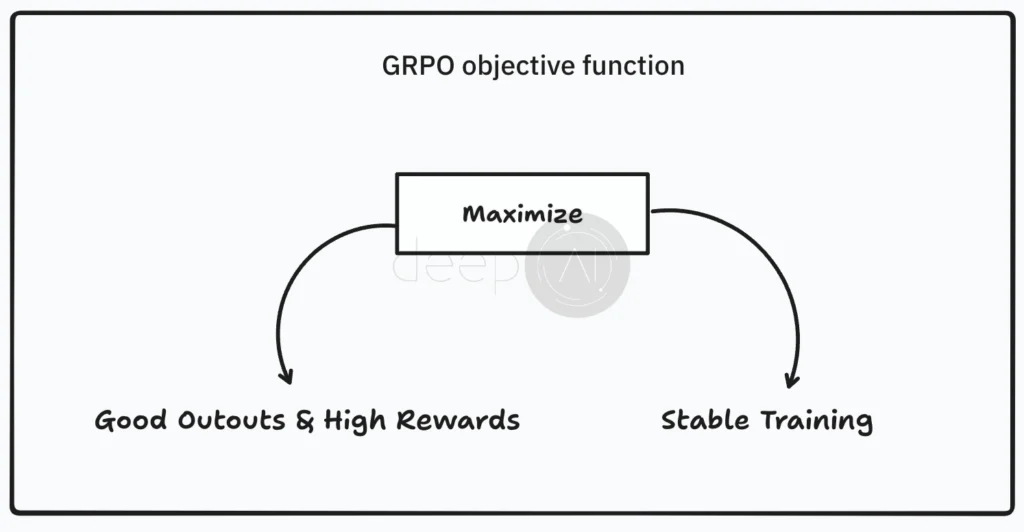
The main goal of GRPO’s objective function is twofold: it aims to produce good outputs (or high rewards) while keeping the training process stable. Now, let’s simplify how it works.

First, we have AverageResult[…] or 1/n[…] , which looks at what happens on average across different situations. We present the model with various questions, and for each question, it generates a set of answers. By examining these answers across multiple questions, we can calculate an average result.
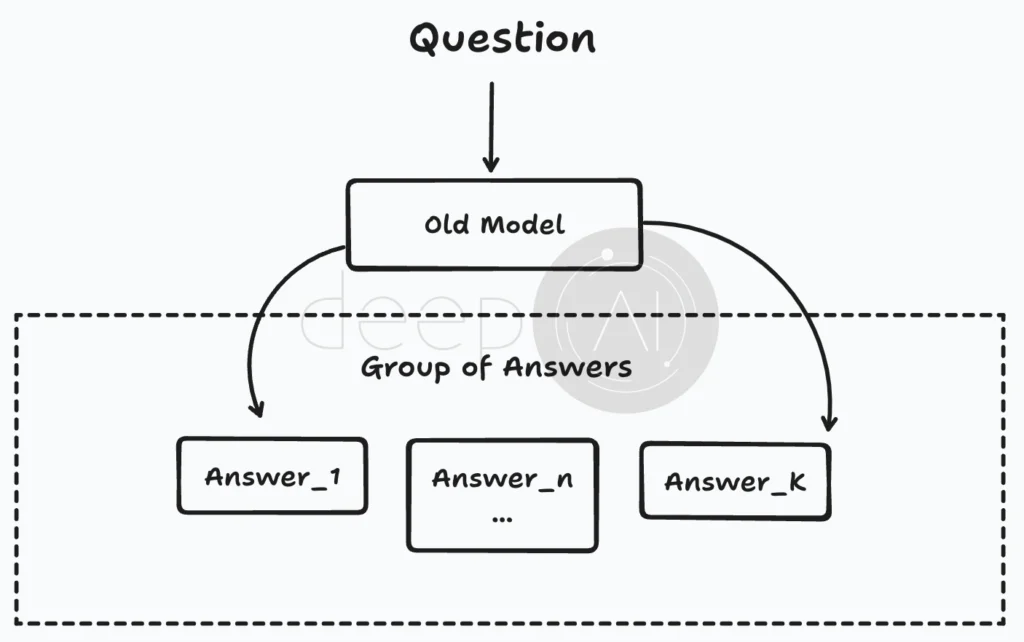
In this process, the question goes to an older model that produces several answers (like Answer 1, Answer 2, and so on). These answers form a group, and by evaluating this group across different questions, we find the average outcome.
Next up is SumOf[…] or ∑[…], which means we calculate something for each answer in the group and then add all those results together.
Now, let’s dive into the RewardPart. This part rewards the model for providing good answers, and it has a few layers to it.
First, we have ChangeRatio, which tells us if the likelihood of giving a certain answer has increased or decreased with the new model. It compares:
- The chance of the new model giving a specific answer.
- The chance of the old model giving the same answer.
Then, we have the Advantage score, which shows how much better or worse an answer is compared to others in the same group. It’s calculated using:
- The score given to the specific answer.
- The average score of all answers in the group.
- The variation in scores within the group.
The Advantage score helps us see if an answer is above average and by how much. It’s calculated as:

Next is LimitedChangeRatio, which is a tweaked version of ChangeRatio. It keeps the ChangeRatio from swinging too wildly, ensuring the model learns steadily. This limit is set by a small value called Epsilon, which prevents drastic changes.
Finally, we have the SmallerOf function, which picks the smaller value between two options:
- ChangeRatio × Advantage: The change in likelihood of an answer multiplied by its advantage score.
- LimitedChangeRatio × Advantage: The same, but with a limited change ratio.
By choosing the smaller value, the model keeps the learning process smooth and avoids overreacting to big performance changes. This results in a “good answer reward” that encourages improvement without going overboard.
Lastly, we subtract the StayStablePart, which helps the new model avoid drastic changes from the old one. It’s not too complex, but let’s break it down:

DifferenceFromReferenceModel measures how much the new model differs from the old one. It helps us see the changes the new model has made compared to the previous version.
The Beta value controls how closely the model should stick to the old model’s behavior. A larger Beta means the model will try harder to stay close to the old model, preventing too much deviation.

In short, StayStablePart ensures the model learns gradually and doesn’t make wild jumps.
Reward Modeling for DeepSeek R1 Zero
Now that we’ve covered the main ideas, let’s dive into how the reward modeling works for R1 Zero. They kept things straightforward. Instead of using a complex neural network to evaluate answers, they opted for a simple rule-based reward system.
Take our math problem: “What is 2 + 3 * 4?” The system knows the correct answer is 14. It checks the output from DeepSeek V3 (our reinforcement learning agent) and looks specifically at the
If the
DeepSeek R1 Zero also needed to learn how to structure its reasoning. For that, it uses
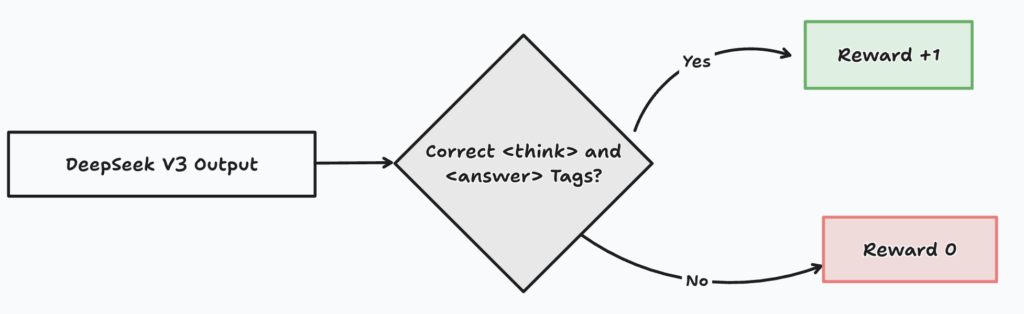
The DeepSeek R1 paper specifically mentions avoiding neural reward models to prevent reward hacking and keep things simple during this early phase.
Training Template for Reward
To make the reward model work well, researchers created a training template. This template serves as a guide for DeepSeek-V3-Base on how to respond during the Reinforcement Learning process.
Let’s break down the original template:
A conversation between User and Assistant. The user asks a question, and
the Assistant solves it. The assistant first thinks about the reasoning
process in the mind and then provides the user with the answer. The reasoning
process and answer are enclosed within <think> </think> and <answer> </answer>
tags respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: {prompt}. Assistant:The {prompt} is where we plug in our math problem, like What is 2 + 3 * 4?. The important part is those <think> and <answer> tags. This structured output is super important for researchers to peek into the model’s reasoning steps later on.
When training DeepSeek-R1-Zero, we use this template with prompts. For our math problem, the input would look like this:
A conversation between User and Assistant. The user asks a question, and
the Assistant solves it. The assistant first thinks about the reasoning
process in the mind and then provides the user with the answer. The reasoning
process and answer are enclosed within <think> </think> and <answer> </answer>
tags respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: What is 2 + 3 * 4?. Assistant:We expect the model to generate an output that fits the template, like:
<think>
Order of operations:
multiply before add. 3 * 4 = 12. 2 + 12 = 14
</think>
<answer>
14
</answer>
Interestingly, the DeepSeek team kept this template simple, focusing on structure rather than dictating how the model should reason.
RL Training Process for DeepSeek R1 Zero
Here’s a look at the RL training process for the DeepSeek R1 Zero. While the paper doesn’t detail the exact initial dataset for reinforcement learning (RL) pre-training, we think it should focus on reasoning.
The first step involved generating several possible outputs using the previous policy, which is the DeepSeek-V3-Base model, before any RL updates. In one training round, we assume that GRPO samples a group of four outputs (G = 4).
For instance, when the model processes the question “What is 2 + 3 * 4?”, it might produce these four outputs:
- o1:
2 + 3 = 5, 5 * 4 = 20 20 (Incorrect order of operations) - o2:
3 * 4 = 12, 2 + 12 = 14 14 (Correct) - o3:
14 (Correct, but missingtags) - o4:
…some gibberish reasoning… 7 (Incorrect and poor reasoning)
Every output will be assessed and given a score based on how accurate and well-reasoned it is. To help improve the model’s reasoning, we use a rule-based reward system. Each response gets a reward based on two main factors:
- Accuracy Reward: This checks if the answer is correct.
- Format Reward: This looks at whether the reasoning steps are properly formatted with
tags.
Here’s how the rewards are assigned:
| Output | Accuracy Reward | Format Reward | Total Reward |
|---|---|---|---|
| o1 (Incorrect reasoning) | 0 | 0.1 | 0.1 |
| o2 (Correct with reasoning) | 1 | 0.1 | 1.1 |
The model aims to improve by favoring outputs that earn higher rewards while minimizing the chances of producing incorrect or incomplete results. To see how each output affects the model’s performance, we calculate the advantage using the reward values. This advantage helps optimize the policy by reinforcing better outputs.
First, let’s find the mean reward:
Mean Reward = (0.1 + 1.1 + 1 + 0.1) / 4 = 0.575
Next, we approximate the standard deviation as 0.5. Now, we can calculate the advantage for each output. Outputs o2 and o3 show positive advantages, meaning they should be encouraged. In contrast, outputs o1 and o4 have negative advantages, indicating they should be discouraged.
Using these calculated advantages, GRPO updates the policy model (DeepSeek-V3-Base) to boost the likelihood of generating outputs with high advantages (like o2 and o3) while reducing the chances of outputs with low or negative advantages (like o1 and o4). The update adjusts the model weights based on:
- Policy Ratios: The probability of generating an output under the new policy compared to the old one.
- Clipping Mechanism: This prevents overly large updates that could destabilize training.
- KL-Divergence Penalty: Ensures updates don’t stray too far from the original model.
This process ensures that in the next round, the model is more likely to produce correct reasoning steps while cutting down on incorrect or incomplete responses. Reinforcement Learning (RL) is an iterative process, and these steps are repeated thousands of times with different reasoning problems. Each iteration gradually enhances the model’s ability to:
- Follow the correct order of operations
- Provide logical reasoning steps
- Use the proper format consistently
The overall training loop looks like this:
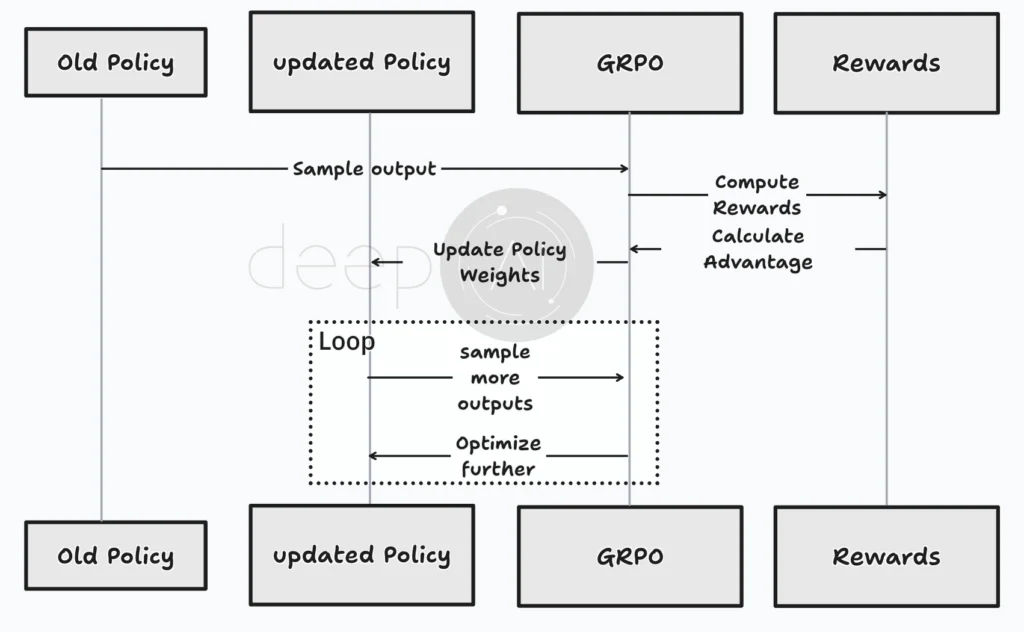
Over time, the model learns from its mistakes, becoming more accurate and effective at solving reasoning problems. 🚀
Two main problems with R1 Zero
After creating DeepSeek-R1 Zero using a reinforcement learning (RL) training process on the V3 model, researchers found that it performed impressively on reasoning tests.
In fact, it scored similarly to more advanced models like OpenAI-01–0912 on tasks such as AIME 2024. This success highlighted the potential of using RL to enhance reasoning in language models.
However, the team also identified some significant issues that needed to be addressed for practical use and further research.
The first problem was that the reasoning processes within the
These two main challenges prompted the researchers to evolve their initial R1 Zero model into the R1 model. In the next section, we’ll explore how they improved the R1 model, enhancing its performance and enabling it to surpass all other models, both open-source and closed.
To tackle the issues with R1 Zero and ensure DeepSeek could reason effectively, the researchers conducted a Cold Start Data Collection and incorporated Supervised Fine Tuning. This approach can be seen as laying a solid foundation for the model’s reasoning skills before diving into more intense RL training.
Essentially, they aimed to teach DeepSeek-V3 Base what effective reasoning looks like and how to present it clearly.
Related — DeepSeek API: Comprehensive Guide to Availability, Usage, and Comparison
Cold Start Data
To tackle the R1 Zero issues and improve DeepSeek’s reasoning, researchers kicked off a Cold Start Data Collection and added Supervised Fine Tuning. Think of it as laying a solid groundwork for the model’s reasoning skills before diving into the more challenging reinforcement learning (RL) training. They aimed to show DeepSeek-V3 Base what effective reasoning looks like and how to communicate it clearly.
Few-Shot Prompting with Long CoT
Next, they introduced DeepSeek-V3 Base to a few sample questions paired with detailed, step-by-step solutions, known as Chain-of-Thought (CoT).
The goal was for the model to learn from these examples and start mimicking this methodical reasoning approach.
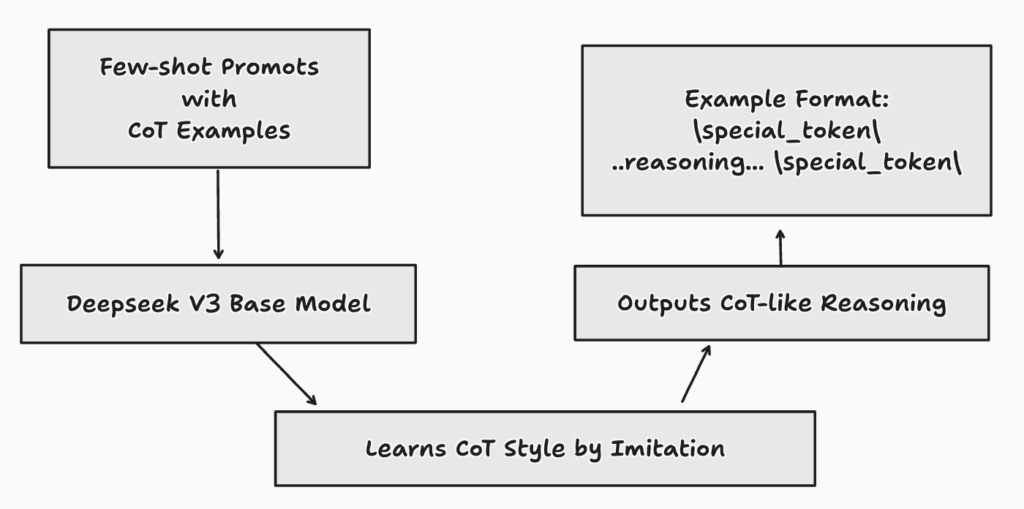
To illustrate this example-based learning, consider the problem: What is 2 + 3 * 4? They might present prompts like this:
Problem Examples with Solutions:
Problem: What's the square root of 9 plus 5?
Solution: | special_token | First, find the square root of 9, which is 3.
Then, add 5 to 3. 3 + 5 equals 8. | special_token | Summary: The answer is 8.
Problem: Train travels at 60 mph for 2 hours, how far?
Solution: | special_token | Use the formula: Distance = Speed times Time.
Speed is 60 mph, Time is 2 hours. Distance = 60 * 2 = 120 miles.
| special_token | Summary: Train travels 120 miles.
Problem: What is 2 + 3 * 4?
Solution:
Those | special_token | things are just markers to separate the reasoning steps from the summary, making it clear for the model to learn the structure.
After seeing these examples, the model should learn to give answers in a similar format, like this for What is 2 + 3 * 4?
| special_token | Following order of operations (PEMDAS/BODMAS),
do multiplication before addition. So, first calculate 3 * 4 = 12.
Then, add 2 to 12. 2 + 12 = 14. | special_token | Summary: The answer is 14.
Direct prompting
Direct prompting was another method they used to collect data. They asked the model to solve problems while also explaining its reasoning step-by-step and then verifying its answer. This approach aimed to encourage more careful and thoughtful problem-solving.
For example, to solve the question “What is 2 + 3 * 4?”, the prompt might look like this:
Problem: Solve this, show reasoning step-by-step, and verify:
What is 2 + 3 * 4?
And they do expect an output that includes both reasoning steps and a verification part:
| special_token | Reasoning: To solve 2 + 3 * 4, I need to use order of
operations. Multiplication comes before addition.
Step 1: Calculate 3 * 4 = 12.
Step 2: Add 2 to the result from step 1: 2 + 12 = 14.
Verification: Checking order of operations again, yes, multiplication
is before addition. Calculation looks right.
| special_token | Summary: The answer is 14.
Post Processing Refinement
They used outputs from the R1 Zero model, even though it had some issues. R1 Zero could reason a bit, so they took its outputs and had human annotators clean them up. This made the outputs clearer, more structured, and corrected any mistakes.
For example, a messy output from R1 Zero might look like this:
<think> ummm... multiply 3 and 4... get 12... then add 2...</think>
<answer> 14 </answer>Humans would refine it to something like:
| special_token | Reasoning: To solve this, we use order of operations,
doing multiplication before addition.
Step 1: Multiply 3 by 4, which is 12.
Step 2: Add 2 to the result: 2 + 12 = 14.
| special_token | Summary: The answer is 14.This refinement process worked well for several reasons:
- High-Quality Reasoning Examples: Each example showed clear, step-by-step reasoning.
- Consistent, Readable Format: The | special_token | format made everything uniform and easy to read.
- Human-Checked: They filtered out any bad examples, ensuring the data was clean and reliable.
After gathering this Cold Start Data, they moved on to Supervised Fine-Tuning (SFT).
Supervised Fine-Tuning
The main goal of SFT Stage 1 is to teach the DeepSeek-V3-Base model how to produce high-quality, structured reasoning outputs. Essentially, they show the model many examples of good reasoning and ask it to learn to imitate that style.
For SFT, they format the Cold Start Data into input-target pairs. For each reasoning problem, they create a pair like this:
User: What is 2 + 3 * 4? Assistant:This is what they feed into the model, and the target is the well-structured reasoning and answer:
| special_token | According to the order of operations (PEMDAS/BODMAS) ...
Summary: The answer is 14.This is the ideal output they want the model to learn to generate. They’re telling the model: when you see this input (the question), we want you to produce this target output (the good reasoning and answer).
To make it easier to understand, let’s visualize the SFT process. It starts with Input: Prompt + Target Reasoning, where they provide a question and a structured reasoning example. This trains the DeepSeek-V3-Base Model to generate well-structured responses.
In the Predict Next Token step, the model generates the next word in the reasoning sequence. They compare this to the actual next token using a loss function. A higher loss means the prediction was further from the correct token.
In the Update Model Parameters step, backpropagation and an optimizer adjust the model’s weights to improve its predictions. This process loops back, repeating over many input-target pairs, gradually enhancing the model’s structured reasoning skills with each iteration.
Reasoning-Oriented RL
After giving DeepSeek V3 a reasoning education through SFT, researchers introduced Reasoning-Oriented Learning to sharpen its skills even more. They took the fine-tuned DeepSeek-V3 model and pushed it to improve through Reinforcement Learning.
They used the same GRPO algorithm, but the big upgrade here was the Reward System. They added something crucial: Language Consistency Rewards! Remember how R1 Zero sometimes mixed up languages? To fix that, they introduced a reward for keeping the language consistent. The idea is simple: if you ask a question in English, the reasoning and answer should also be in English.
Let’s visualize how this Language Consistency Reward works:
To understand the rewards, let’s revisit our example outputs o1 and o2. We’ll assume the target language is English for simplicity. For the first output, o1, which incorrectly calculates “2 + 3 * 4” but presents its reasoning in English:
<think> 2 + 3 = 5, 5 * 4 = 20 </think> <answer> 20 </answer>This output gets an accuracy reward of 0 because the answer is wrong. However, since the reasoning is in English, it receives a language consistency reward of 1. So, the total reward for o1 becomes:
Total Reward = (1 * Accuracy Reward) + (0.2 * Language Consistency Reward)
(1 * 0) + (0.2 * 1) = 0.2Now, consider output o2, which correctly solves the problem and reasons in English:
<think> 3 * 4 = 12, 2 + 12 = 14 </think> <answer> 14 </answer>This output earns a perfect accuracy reward of 1. Assuming its reasoning is also in English, it gets a language consistency reward of 1. Using the same weights as before, the total reward for o2 is:
(1 * 1) + (0.2 * 1) = 1.2Notice how the language consistency reward slightly boosts the total reward for the correct answer and even gives a small positive reward for the incorrect answer o1, as long as it maintains language consistency.
This RL training loop follows the same DeepSeek R1 Zero training loop we saw earlier:
- Generate multiple outputs.
- Refine rewards, including Language Consistency.
- Use GRPO for advantage estimation.
- Train the model to favor high-advantage outputs.
- Repeat the process!
Rejection Sampling
To improve their reasoning data, the DeepSeek team aimed to gather the best examples for training their model. They used a method called Rejection Sampling to achieve this.
For our question “What is 2 + 3 * 4?”, they generated multiple outputs from the previous model.
They then checked each output for accuracy and how well the reasoning was explained. Only the top-quality answers that were correct and well-reasoned were kept, while the rest were tossed out.
For more complex reasoning, they employed a Generative Reward Model to assess the quality of the reasoning. They used strict filters to eliminate mixed languages, rambling explanations, or irrelevant code. This process resulted in around 600,000 high-quality reasoning samples.
In addition to this refined reasoning data, they included about 200,000 Non-Reasoning Data samples for general skills like writing, question answering, and translation, sometimes using Chain-of-Thought for more complicated tasks.
Next, in SFT Stage 2, they trained the previous model checkpoint on this combined dataset (refined reasoning plus non-reasoning) using next-token prediction. This stage further enhanced reasoning by using the best examples from rejection sampling while also making the model more versatile for a wider range of tasks, all while keeping it user-friendly.
`Now, “What is 2 + 3 * 4?” is a perfectly refined reasoning example included in the training data. This is the essence of Rejection Sampling: we’re filtering out the weaker samples and keeping only the best to create high-quality training data.
RL for All Scenarios
After completing SFT Stage 2, DeepSeek V3 was able to reason, speak consistently, and handle general tasks quite well! But to elevate it to a top-tier AI assistant, the team focused on aligning it with human values through Reinforcement Learning for All Scenarios (RL Stage 2). Think of this as the final touch to ensure DeepSeek R1 is truly safe.
For our example, “What is 2 + 3 * 4?”, while accuracy rewards still promote correct answers, the reward system now also looks at:
- Helpfulness: This checks if the generated summary provides useful context beyond just the answer.
- Harmlessness: This evaluates the entire output for safety and bias, often using separate reward models trained on human preferences.
The final reward signal combines scores for accuracy, helpfulness, and harmlessness.
Now, the training data includes a diverse mix of reasoning problems, general QA prompts, writing tasks, and preference pairs where humans indicate which of two model outputs is better in terms of helpfulness and harmlessness.
The training process follows an iterative RL loop (likely using GRPO) to optimize the model based on this combined reward signal from the varied data.
After many training iterations, the model strikes a balance between reasoning performance and alignment (helpfulness/harmlessness).
Once this balance is achieved, the model is tested on popular benchmark datasets and outperforms other models. The final, highly optimized version is named DeepSeek-R1.
Distillation
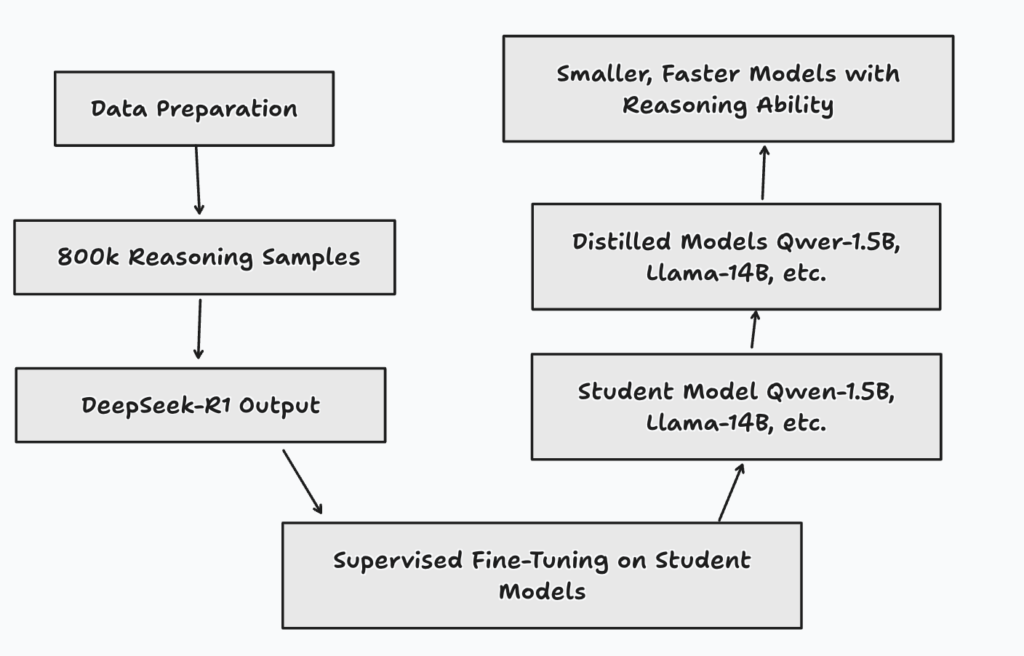
Once the DeepSeek team created a well-performing DeepSeek R1, they distilled it into smaller models for the community, enhancing performance. Here’s how the distillation process works:
- Data Preparation: They gathered 800,000 reasoning samples.
- DeepSeek-R1 Output: For each sample, the output from the teacher model (DeepSeek-R1) serves as the target for the student model.
- Supervised Fine-Tuning (SFT): The student models (like Qwen-1.5B and Llama-14B) are fine-tuned on these 800,000 samples to match the output of DeepSeek-R1.
- Distilled Models: The student models are distilled into smaller versions while retaining much of DeepSeek-R1’s reasoning capability.
The result? Smaller, faster models with solid reasoning abilities, ready for deployment.
I hope this detailed article gives you a clear understanding of how R1 was created. Join us to the DeepAI Family!