Multiple Instance Learning: Exploring Applications, Performance Measures, and Attention Mechanisms
Welcome to our post on Multiple Instance Learning (MIL) – an innovative approach that has revolutionized the field of machine learning. In this article, we will delve into the concepts of MIL, explore its applications, and shed light on the performance measures and characteristics associated with this fascinating technique.
We will also uncover the structural aspects and algorithms involved in MIL, while gaining a deeper understanding of attention mechanisms. Additionally, we will explore the exciting realm of Deep Multiple Instance Learning in the context of healthcare.
So, whether you’re a seasoned expert or a curious beginner, join us as we unravel the intricacies of Multiple Instance Learning and its immense potential in various domains. Let’s dive in!
Concepts of Multiple Instance Learning
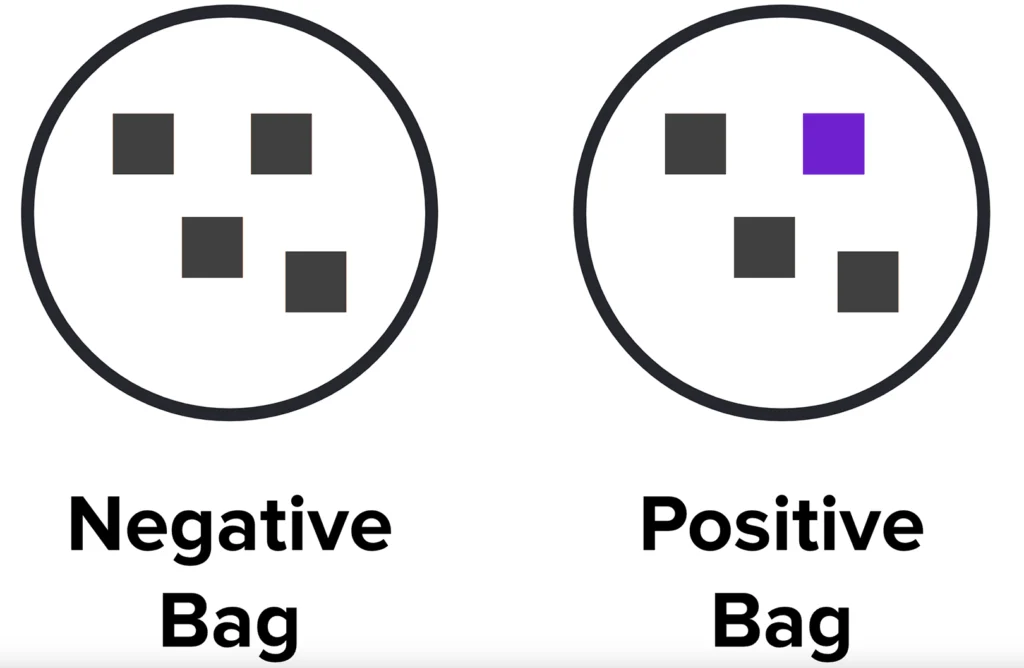
Multiple Instance Learning (MIL) is a fascinating subset of machine learning that has been gaining traction due to its unique approach to handling weakly labeled data. To fully understand the essence of MIL, it’s important to delve deeper into its underlying principles and the way it operates.
At its core, MIL is a form of weakly supervised learning. However, it stands out from other machine learning techniques due to its distinctive method of managing instances. Rather than labeling instances individually, MIL organizes them into groups, or ‘bags’ as they are commonly referred to. Each bag is then assigned a single label, which represents the collective data within. This approach is particularly beneficial when dealing with large datasets where individual labeling can be a costly and time-consuming endeavor.
The strength of MIL lies in its ability to leverage weakly labeled data. In many business scenarios, labeling data accurately can be an expensive affair. MIL, with its bag-based approach, reduces the associated costs and complexities, making it an efficient tool for tackling various business problems.
There’s an interesting analogy that can help to better understand the concept of MIL. Imagine a bag filled with a mix of keys, where only some keys can open a specific door. The bag, as a whole, is labeled as a ‘door-opener.’ However, not every key in the bag can open the door. The challenge then lies in identifying those specific keys that can indeed open the door. This is exactly what MIL does with data – it identifies the ‘key’ instances that contribute to the overall label of the bag.
Moreover, the beauty of MIL is that it doesn’t stop at merely identifying the relevant instances. It uses these instances to train the machine learning model, enabling it to make accurate predictions when faced with new, unseen data. This ability to learn from weakly labeled data and make accurate predictions is what makes MIL a powerful tool in the realm of machine learning.
Overall, the unique approach of MIL in leveraging weakly labeled data has made it an attractive choice for many businesses and researchers, offering a cost-effective and efficient solution to many real-world problems.
Applications of Multiple Instance Learning (MIL)
Multiple Instance Learning (MIL) has proven to be a versatile tool, finding applications in a wide array of fields. Its ability to handle weakly labeled data, reducing the need for extensive individual labeling, makes it an attractive choice in many scenarios. Let’s delve deeper into its applications across various domains.
In the realm of medical imaging, MIL has revolutionized computer-aided diagnosis. It allows for the efficient analysis of images, identifying diseased regions based on patient diagnoses. This approach eliminates the need for detailed local annotations, thereby speeding up the diagnostic process and reducing the chance of human error.
MIL also plays a significant role in video/audio analysis. In situations where only tags for an entire video or audio piece are available, MIL can identify specific elements within the content. This capability is particularly useful in the entertainment industry for content categorization and in security surveillance for threat detection.
In the world of digital marketing, MIL can help identify potential customers influenced by a particular campaign. By analyzing several data points, it can predict which individuals are more likely to respond positively to specific marketing strategies, thereby improving campaign efficiency.
When it comes to document classification, MIL is a game-changer. It can determine whether a website focuses on a specific topic by analyzing multiple web pages, even those with potentially irrelevant information. This feature is particularly beneficial in search engine optimization, helping to improve a website’s ranking and visibility.
Moreover, in time series analysis, MIL proves to be a powerful tool. It can estimate amounts at a more granular level based on total monthly data, such as gas or water consumption. This application can be instrumental in resource management and conservation efforts.
By taking a closer look at these applications, it’s clear that MIL’s potential is vast, spanning multiple industries and sectors. Its unique approach to handling weakly labeled data not only simplifies the learning process but also opens up new avenues for problem-solving in the real world.
Performance Measures In MIL for Classification: A Deeper Look
When we delve into the realm of Multiple Instance Learning (MIL), we find a substantial body of literature that is primarily focused on its classification applications. While it’s true that MIL also has a significant role in regression, ranking, and clustering, these topics fall outside the scope of our present discussion. Instead, we’ll concentrate on how MIL excels in tackling classification problems, a facet that has garnered much attention in the machine learning community.
Imagine a scenario where positive bags cannot be identified by a single instance. Instead, they require a collective analysis of multiple instances to be accurately classified. This is where the flexibility of MIL becomes a game-changer. It can adapt to such situations, providing a solution that conventional learning techniques might struggle with.
Let’s take an example from the field of medical imaging, where the task is to identify whether a patient has a specific disease based on a series of medical images. A traditional machine learning approach would require each image to be labeled individually – a time-consuming and costly process. However, with MIL, one can label a whole set (or bag) of images at once, significantly reducing the time and cost involved. If any image in the bag indicates the disease, the whole bag is labeled as positive. This is an example of how MIL’s classification potential is leveraged in real-world scenarios.
In the realm of digital marketing, MIL is employed to classify user behavior patterns. Instead of analyzing each user action individually, MIL groups these actions into bags. If a bag contains any instance of a user engaging with a product or service, the entire bag is classified as positive. This approach allows marketers to efficiently identify potential customers and enhance their marketing strategies.
Thus, MIL’s ability to handle complex classification problems, coupled with its flexibility and efficiency, makes it a highly sought-after learning technique in the world of machine learning.
Digging Deeper into the Characteristics and Assumptions of Multiple Instance Learning (MIL)
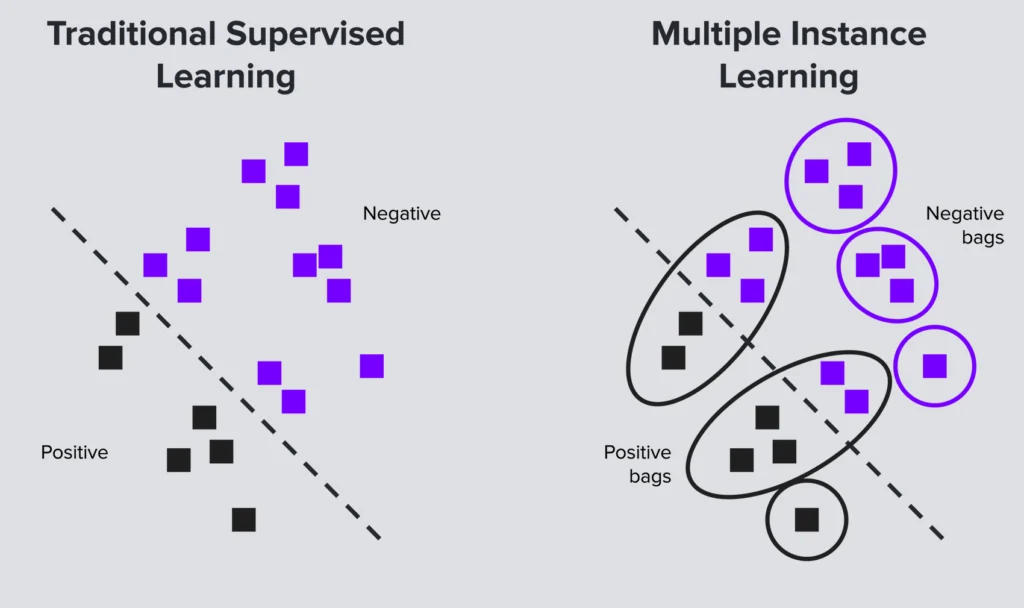
At its core, Multiple Instance Learning (MIL) is a novel approach to machine learning, which is primarily characterized by its unique organization of instances into ‘bags’. This method of categorization is distinctive to MIL and forms the basis of its operational framework. In this context, a negative bag is exclusively filled with negative instances, while a positive bag houses at least one positive instance, often fondly termed as a ‘witness’.
What sets MIL apart from other machine learning techniques is its inherent assumption of independent sampling of positive and negative instances.
However, this assumption often deviates from the reality of data collection and analysis. In real-world scenarios, instances within the same bag tend to share certain similarities, which starkly contrast with instances from other bags.
This leads to the emergence of specific correlations and semantic relations, which become pivotal in the process of MIL.
For instance, consider a scenario where certain subjects are more likely to appear in specific environments, or certain objects are usually found together. These correlations are not mere coincidences but are indicative of the underlying patterns and trends, which MIL adeptly captures and utilizes for further analysis.
Despite its assumptions, MIL’s ability to recognize and leverage these correlations makes it an incredibly powerful tool. Its ability to sift through vast amounts of data and identify meaningful patterns and trends is what sets it apart. This makes it highly valuable in various fields such as medical imaging, document classification, marketing, and time series analysis.
However, it’s important to note that while MIL is incredibly effective, its assumptions and characteristics also pose unique challenges that need to be addressed. Understanding these nuances is crucial for anyone looking to harness the power of MIL for their data analysis needs.
Structural Aspects of Multiple Instance Learning
Multiple Instance Learning (MIL) is a valuable asset when individual instance labeling proves to be a daunting or expensive task. However, it is the unique structural perspective that MIL brings to the table that truly sets it apart. This structure, often manifested in temporal, spatial, relational, or causal forms, is the backbone of the MIL process.
Let’s delve into the intricacies of this structure. Imagine you are tasked with identifying specific frames in a video where a cat appears. The only information you have is that the video contains a cat, nothing more.
In this scenario, the entire video is considered a ‘bag’, with each frame serving as an ‘instance’.
The instances aren’t labeled individually, rather they are organized in a temporal and spatial sequence. This is the core concept of MIL’s structure – instances are grouped into bags, and these bags are labeled as a whole.
But the beauty of MIL lies not just in its simplicity, but in its adaptability. This structure isn’t rigid but flexible, molding itself to fit varying contexts. For instance, in a medical setting, a bag could represent a patient, with instances being different medical tests. In a marketing context, a bag could be a customer, with instances being different purchasing behaviors. The possibilities are virtually endless, and this adaptability is what makes MIL a powerful tool across diverse fields.
However, it’s important to remember that the instances within a bag are not completely independent. They share correlations and similarities, forming a complex web of interconnections that can be leveraged to unearth meaningful patterns and trends. This is a crucial aspect of MIL that is often overlooked, but it is the key to unlocking the full potential of this machine learning technique.
So, while the structural aspects of MIL may seem straightforward at first glance, it’s only when we delve deeper that we begin to appreciate the complexity and versatility of this learning technique.
Drilling Down into the Algorithms in MIL
One can’t overemphasize the importance of algorithms in Multiple Instance Learning (MIL). The accuracy of bag labels is paramount to the effectiveness of these algorithms. Yet, in the dynamic and complex world of MIL, there are instances when positive instances are erroneously tagged as negative, either due to labeling errors or the unavoidable noise that comes with large data sets.
It’s essential to understand that MIL is not about classifying individual instances, but rather bags of instances. This is a unique approach that sets MIL apart from other machine learning paradigms. The bag-level classification models are the backbone of MIL, with each model having its unique way of representing and classifying bags.
For instance, the Bag of Words approach is a widely used model in MIL. It represents bags by their instances and uses a histogram of instance frequencies for classification. This method is particularly effective in text classification tasks where words are treated as instances and documents as bags.
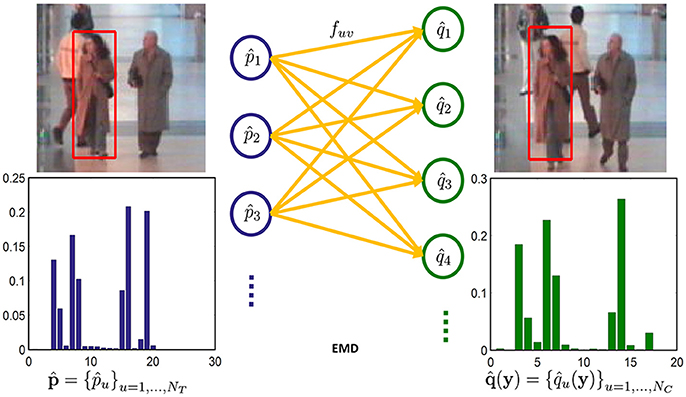
On the other hand, the Earth Mover Distance Support Vector Machine (EMD-SVM), another popular model, measures the dissimilarity between distributions of instances. It uses a Support Vector Machine (SVM) to classify bags, providing a robust and efficient way to handle complex patterns and trends within data.
Label noise, which can arise from varying densities of positive events in different bags or different durations of a tagged event in audio recordings, is a common challenge in MIL. However, the resilience of the MIL algorithms in handling such noise is what makes them indispensable in various fields like computer vision and natural language processing.
As we continue to explore the vast landscape of MIL, it’s clear that the role of algorithms is not just significant, but absolutely critical. They form the bedrock on which the entire framework of MIL rests, and understanding them is key to unlocking the full potential of this powerful machine learning tool.
The Attention Mechanisms in MIL
Attention mechanisms are the unsung heroes in the realm of Multiple Instance Learning (MIL). They are the underlying force that drives the process of identifying the relevance of a block for a particular tag classification. To put it simply, attention mechanisms serve as the ‘eyes’ of the MIL system, focusing on crucial elements while filtering out irrelevant data. This ability to concentrate on pertinent details and ignore distractions enhances the efficiency and accuracy of the MIL process.
In the intricate dance of MIL, the attention mechanisms work in tandem with a detector and a classifier. These two components operate solely on video-level labels, weaving together separate models. The resultant outputs shed light on the probability and significance of a block in the classification of a specific tag. This unique collaboration creates a robust system capable of handling complex tasks with ease.
One of the most compelling attributes of MIL is its ability to train models effectively with sparse annotations. This feature is akin to finding a needle in a haystack – a daunting task made possible by the power of MIL. However, this strength doesn’t come without its share of challenges. Data representation and handling sparse labels can be quite a hurdle in the path of MIL. But, as every cloud has a silver lining, unique algorithms have been designed to tackle these obstacles head-on and deliver satisfactory results.
For those who aspire to unravel the mysteries of MIL and explore its paradigms, there’s no better way than immersing oneself in an online course. These courses, designed by experts in the field, provide a comprehensive understanding of MIL, its mechanisms, and applications. They equip learners with the tools and techniques to master MIL and leverage its potential to the fullest.
The attention mechanisms in MIL are a vital cog in the machine learning wheel, offering an innovative approach to pattern recognition and classification tasks. As we continue to delve deeper into this fascinating field, the possibilities seem boundless.
Expanding the Horizons of Deep Multiple Instance Learning in Health Care
As we delve deeper into the realm of artificial intelligence, it becomes increasingly apparent that Attention-Based Deep Multiple Instance Learning (MIL) holds a significant place in the future of health care, especially in the context of critical diagnoses such as prostate cancer. The health care industry stands on the brink of a major transformation, driven by the powerful convergence of artificial intelligence, machine learning, and data science. In this scenario, MIL emerges as a potent tool, with its robust capabilities and innovative techniques promising to revolutionize the industry.
The strength of MIL lies in its ability to efficiently handle massive datasets, harnessing the power of GPUs and TPUs for deep learning models. Complemented by the vast resources of cloud computing and the progressive strides in open-source algorithmic development modules, MIL is set to redefine health care. The potential of MIL is not limited to the health care industry; its flexibility and sophisticated techniques make it a promising prospect in the broader world of artificial intelligence and machine learning.
However, the true potential of MIL comes to light when we consider its application in the field of diagnostics. For instance, in the diagnosis of prostate cancer, one of the most prevalent forms of cancer in men, MIL can potentially improve the accuracy and speed of diagnosis. It can also aid in the early detection of the disease, thereby increasing the chances of successful treatment and recovery.
Moreover, the application of MIL extends beyond diagnostics to include treatment planning and patient monitoring. By analyzing patterns in patient data, MIL can help predict the progression of diseases, enabling doctors to customize treatment plans for individual patients. It can also monitor patient recovery, alerting doctors to any anomalies that may indicate a relapse or complications.
Despite these promising prospects, the journey of integrating MIL into health care is not without challenges. Data privacy and security, ethical considerations, and the need for explainable AI are some of the issues that need to be addressed. However, with continued research and development, as well as collaboration between AI experts, health care professionals, and policy makers, these challenges can be overcome.
In conclusion, the role of Attention-Based Deep Multiple Instance Learning in health care is undeniably promising. As we continue to explore and harness the potential of this powerful tool, we are likely to witness a transformation in health care that is as profound as it is beneficial.
— FAQ & TL;TR
Multiple Instance Learning (MIL) is a form of weakly supervised learning where training instances are organized into sets called bags and labeled at the bag-level instead of individually.
MIL allows the use of weakly labeled data, which can be more cost-effective than labeling individual instances. It is applicable in various fields such as medical imaging, document classification, marketing, and time series analysis.
Yes, MIL can be modified for regression, ranking, or clustering problems, but these specific applications are not discussed in the article.
MIL problems often involve classifying bags of instances instead of individual instances. The bag label represents the presence of the entity, and the classification performance may differ from instance-level classification.
Some MIL algorithms include bag-level classification, Bag of Words approach, Earth Mover Distance Support Vector Machine (EMD-SVM), and alternative variations of Support Vector Machines (SVM) such as mi-SVM and MI-SVM.
One thought on “Multiple Instance Learning: Exploring Applications, Performance Measures, and Attention Mechanisms”
Comments are closed.