Forget Fine-Tuning: Meet ACE, The AI That Teaches Itself
Fine-tuning is a standard method to improve how large language models perform their tasks. This technique requires feeding the model a set of new data, which leads to small adjustments in some of its weights, a process that can be resource intensive.
A paper from Stanford shows a different way, stating that you do not need to retrain.
The concept is Agentic Context Engineering, or ACE, and it is a brilliant idea.
ACE does not adjust the weights of the model; instead, it develops the context around the model. This context is what we call the prompt. The model rewrites its own rules as it works, a substitute for retraining.
A Model That Keeps a Notebook
Imagine a model keeping a notebook of what worked, what did not, and what it should try next. Each mistake becomes a written note. Each success becomes a solid rule. That notebook is the context. ACE updates this context with one small “delta” at a time, which allows the model to teach itself.
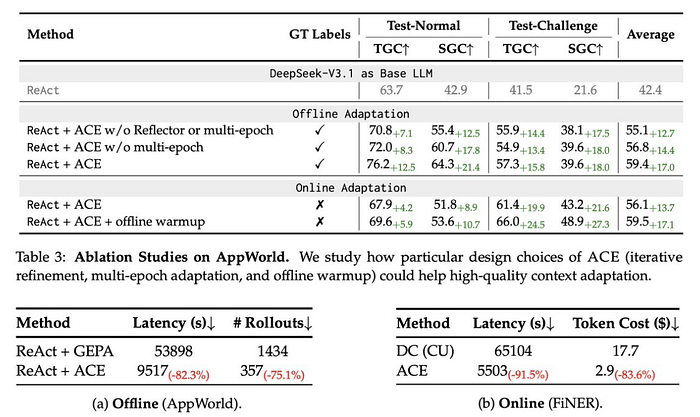
The Crazy Part: It Works
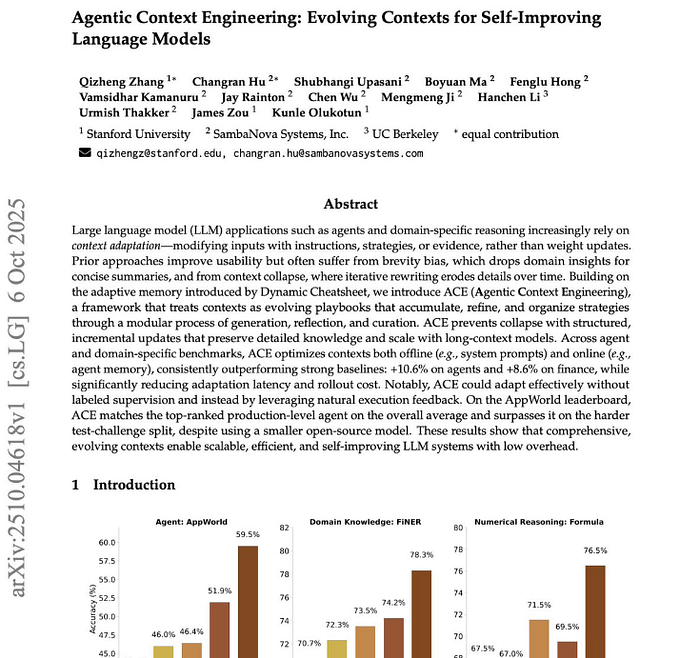
The figures published in the paper show impressive results.
- +10.6% better performance than GPT-4-based agents on AppWorld tasks.
- +8.6% improvement on finance reasoning.
- 86.9% lower cost and latency compared to fine-tuning.
A smaller open-source model using ACE matched the performance of the GPT-4.1–powered IBM CUGA system.
The process required no new data and no labels, relying on reflection and context updates.
So, How Does ACE Actually Work?
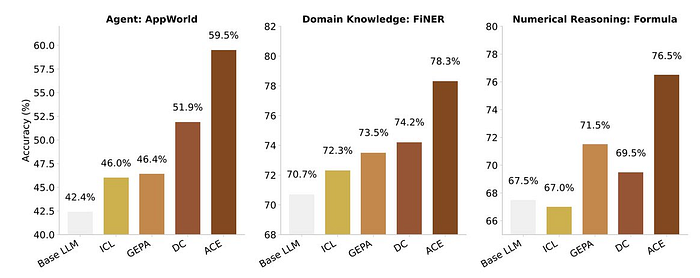
The system has three parts that communicate.
- Generator — runs the main task.
- Reflector — examines the outcome to see what went well or failed.
- Curator — updates the context with only the useful information.
These parts form a feedback loop, a brain cycle that adds small updates instead of overwriting all the information.
Here is a simple version in Python-like pseudocode:
context = []
for task in tasks:
result = model.run(task, context)
review = model.reflect(task, result)
delta = extract_key_lessons(review)
context.append(delta)This context list grows into a personal guidebook the model uses before it solves new problems.
The Old Way vs. ACE
Fine-tuning involves weight updates that are large, expensive, and one-directional. It is hard to see why the model improved.
ACE, in contrast, is like watching the model’s thought process unfold. You see how its understanding develops with each delta.
Previous methods that tried a similar idea had a problem with context collapse. When a model rewrote its full prompt, it lost important details and its performance would get worse. One experiment showed that accuracy dropped from 66.7% to 57.1% after one rewrite.
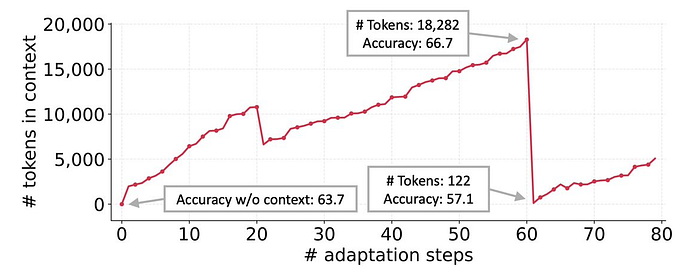
ACE solves this issue because it only patches what needs to change; it never replaces the entire context.
Why It Works: Context Density
The common advice is to “keep your prompts short and clean,” but ACE contradicts this idea.
Large language models do not always prefer short responses. They want responses that are dense with information. The more layered and meaningful the context is, the better the reasoning ability of the model becomes. ACE builds this density through its process of reflection.
From Fine-Tuning to Self-Tuning
This represents a large philosophical shift.
Fine-tuning changes a model’s weights. ACE changes the model’s core understanding.
The process is reversible, transparent, and cheap. We will train contexts instead of models. These systems develop their own memories and adapt across different users, domains, and sessions. Imagine an AI that not only reasons but also recalls.
That is the future that ACE suggests—the era of living prompts.
TL;DR
- No retraining.
- No labels.
- Reflection loops are used.
- Models learn from themselves.
Fine-tuning is not obsolete, but it has a smarter, affordable alternative.