What is the Inception Module and Its Role in Enhancing Deep Learning?
What is the Inception Module in deep learning?
The Inception Module is a vital component in convolutional neural networks (CNNs), first introduced by Google in their groundbreaking 2014 paper titled “Going Deeper with Convolutions.” This innovative design enables the network to process and analyze visual data more effectively by applying multiple convolutional filters of different sizes at the same time. By doing so, it captures various levels of detail and abstraction from the input images, which significantly improves performance in complex computer vision tasks, such as image recognition and object detection.
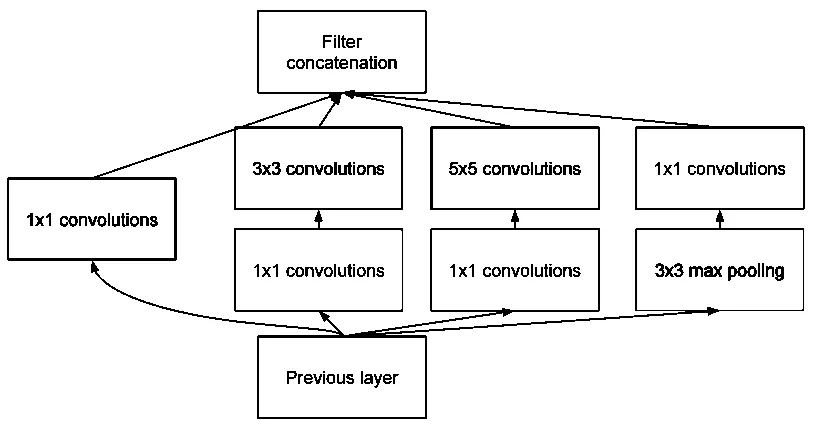
The core idea behind the Inception Module lies in its ability to extract multi-scale features without the need for enormous computational resources. In traditional CNN architectures, the information from an image is typically processed through a series of layers with a consistent filter size, which may overlook crucial features. The Inception Module overcomes this limitation by allowing each layer to use parallel convolution paths with varying filter sizes, such as 1×1, 3×3, and 5×5, alongside a pooling layer. This parallel processing not only enhances feature extraction but also captures a more comprehensive understanding of the spatial hierarchies present in the images.
For example, in a scene that includes both small objects, like a person’s hand, and larger objects, like a car, the Inception Module can extract fine details while also maintaining an awareness of the contextual relationships in the larger patches of the image. Furthermore, statistics from various studies suggest that models utilizing Inception Modules often achieve better top-5 accuracy on benchmark datasets, indicating their effectiveness in real-world applications.
To implement an Inception Module, practitioners typically stack these modules in layers within a CNN architecture. By doing so, users can increase the depth and representational capacity of the model while keeping computational overhead in check. It’s important to note, however, that while Inception Models are powerful, they can be complex, so prior familiarity with CNN architectures is beneficial. Some common pitfalls to avoid include neglecting the careful tuning of hyperparameters, as this can lead to suboptimal performance. Generally, adopting Inception Modules in deep learning frameworks can optimize computer vision tasks, making them an essential technique for anyone looking to enhance their neural network architectures.
How does the Inception Module enable multi-level feature extraction?
The Inception Module enhances multi-level feature extraction by utilizing convolutional filters of varying sizes, such as 1×1, 3×3, and 5×5, within a single layer. This design enables the module to capture and analyze intricate patterns at different spatial resolutions simultaneously.
This innovative approach is significant as it allows the convolutional neural networks (CNNs) to extract a diverse array of features from the input data, thus improving the model’s overall performance. For instance, smaller filters (1×1) are effective for capturing fine details and reducing dimensionality, while larger filters (3×3 and 5×5) help in identifying broader structures or patterns. By processing the same input through various filter sizes, the Inception Module creates a richer feature map that encapsulates both local and global characteristics of the data.
Additionally, this multi-level feature extraction is especially beneficial in complex tasks such as image recognition and classification, where diverse features are crucial for accurate predictions. A notable example of this can be seen in the Inception architecture used in the GoogLeNet model, which won the ImageNet Large Scale Visual Recognition Challenge in 2014, illustrating the practical effectiveness of this technique.
For optimal results when implementing the Inception Module, it is recommended to experiment with different filter sizes and pooling layers based on the specific nature of the dataset. Common pitfalls include overfitting due to excessive complexity and computational resource demands, which can be mitigated through techniques such as dropout and batch normalization. By carefully managing these aspects, users can harness the full potential of the Inception Module for a robust multi-level feature extraction strategy.
More — Hyperparameter Optimization: Understanding Its Impact on Machine Learning Performance
What are the advantages of using the Inception Module?
The Inception Module offers several significant advantages that make it a preferred choice in deep learning models. Primarily, it enhances the efficiency of feature extraction, allowing the model to capture a broad array of features from the input data without the need for a larger number of parameters.
One key point of the Inception Module is its unique architecture, which employs parallel convolutional filters of varying sizes—meaning it can simultaneously extract different types of features at multiple scales. This not only improves the model’s ability to understand complex patterns in the data but also minimizes the risk of overfitting, which is a common challenge in deep learning. By effectively managing the number of parameters while maintaining a high level of performance, the Inception Module strikes a balance between complexity and efficiency.
For example, in tasks like image recognition, you might find that the Inception Module significantly outperforms a standard Convolutional Neural Network (CNN) due to its ability to learn rich feature representations from high-dimensional input images. Additionally, research has shown that models utilizing the Inception architecture can achieve state-of-the-art results on benchmark datasets while maintaining lower computational costs compared to their deeper or wider counterparts.
In practical terms, users can benefit from leveraging the Inception Module by following the best practices of carefully designing the attributes of the various convolutional layers incorporated within. Avoiding common mistakes, such as neglecting to balance the number of filters across the layers, is crucial for maximizing the effectiveness of the module. Furthermore, advanced users can experiment with different configurations of the Inception Module to uncover specific tweaks that optimize performance for their particular applications, ensuring they achieve the best possible results.
What challenges does the Inception Module present?
The Inception Module presents challenges such as increased model complexity, the necessity for precise hyperparameter tuning, and resource intensity due to various operations involved. This complexity can complicate the design and training process, requiring a deeper understanding of neural network architecture and considerable computational resources. Users must also be prepared to invest time in experimenting with different parameter settings to optimize performance, as well as ensure their hardware can accommodate the increased demands associated with using this module effectively.
More — Deep Learning Memory Options: Maximizing RAM and GPU Memory for Optimal Performance
How has the Inception Module evolved since its introduction?
The Inception Module has evolved significantly since its introduction, with versions such as Inception-v2, -v3, and -v4 bringing key advancements like factorized convolutions and residual connections. These enhancements have not only boosted training efficiency but also improved the architecture’s ability to process complex data.
As the Inception Module progressed, each version introduced innovative features that made it more effective for deep learning tasks. For instance, factorized convolutions reduced the computational burden while maintaining performance, allowing for deeper networks without a substantial increase in processing time. Residual connections helped combat the vanishing gradient problem, facilitating better training of deep architectures. Overall, these developments have established the Inception Module as a versatile and powerful tool in various applications, from image recognition to natural language processing.